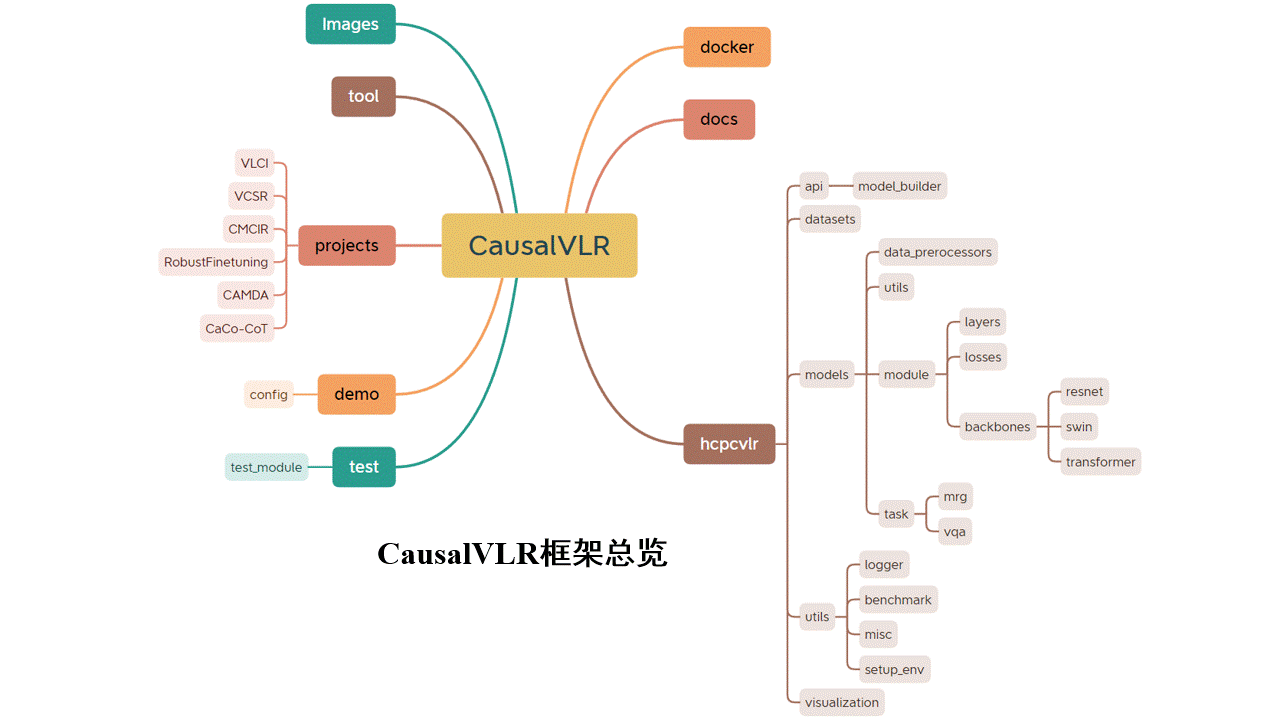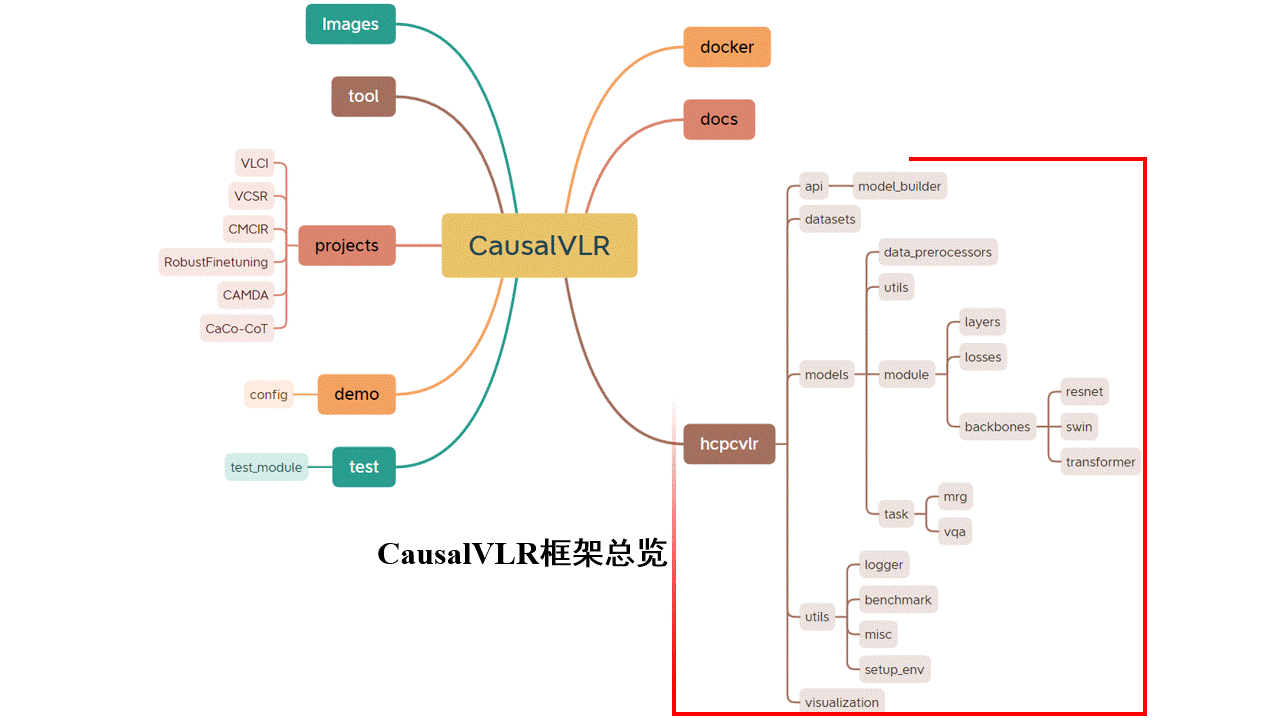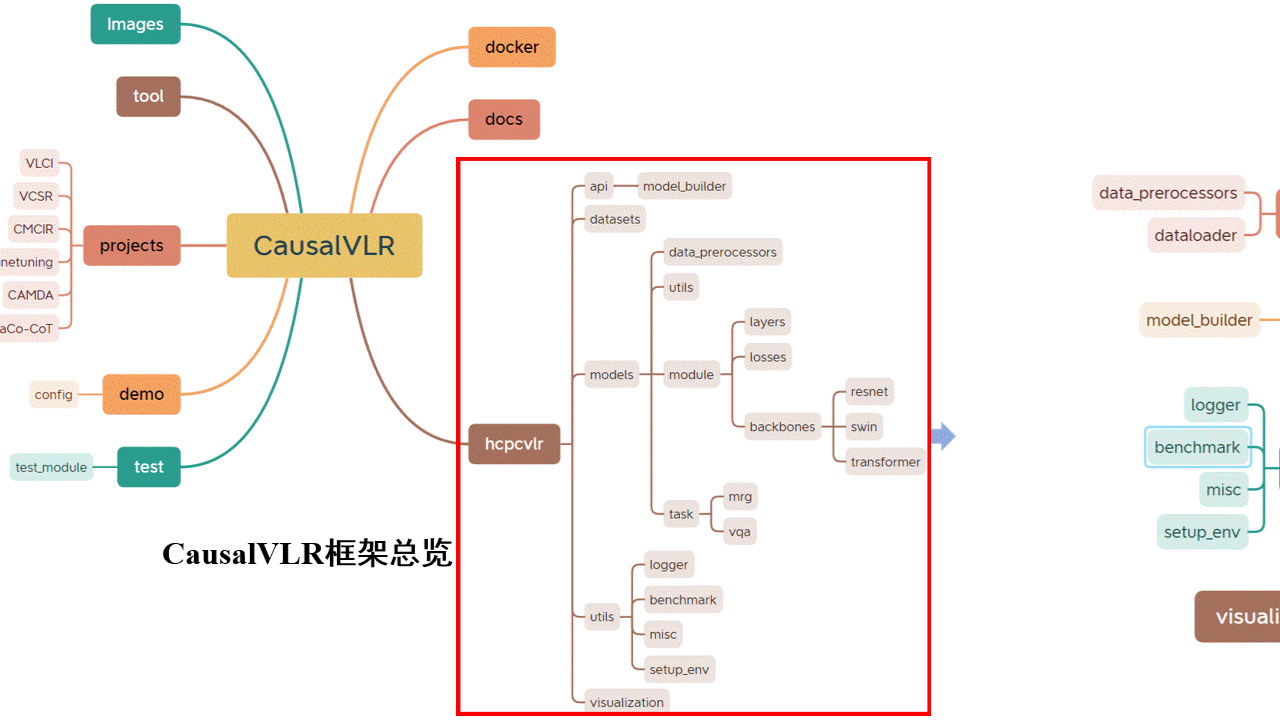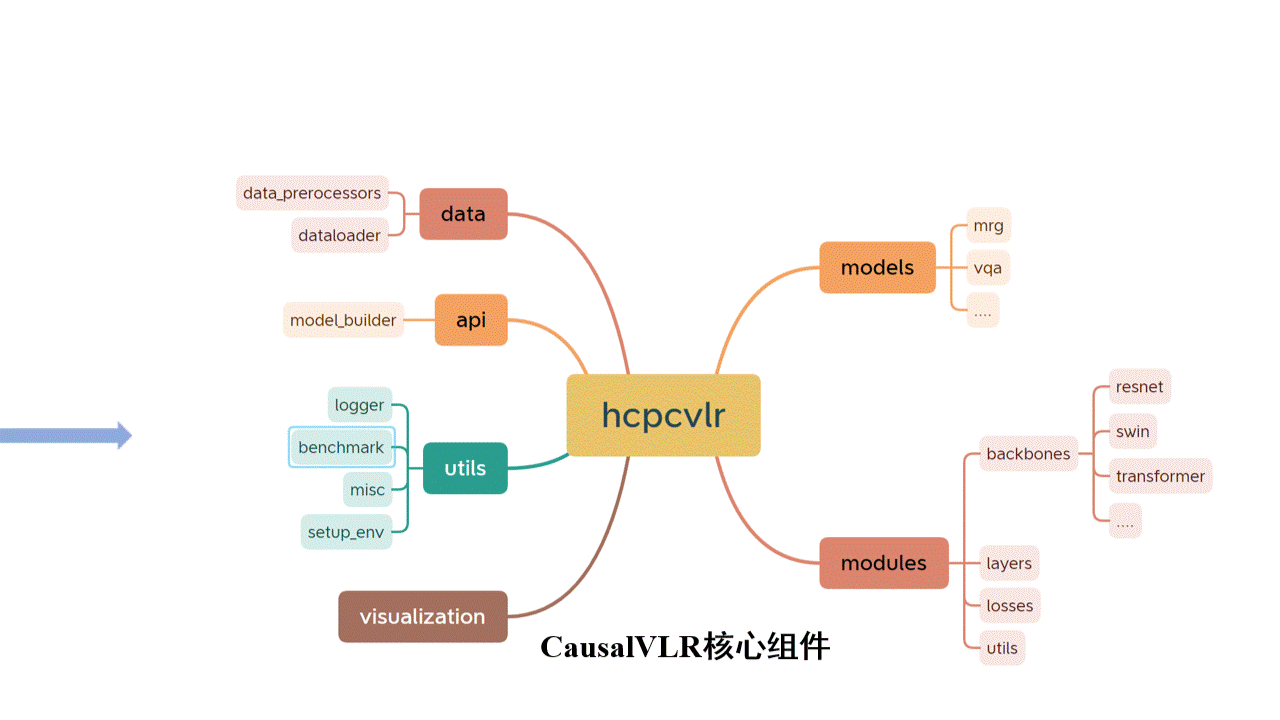
Yang Liu (刘阳)
liuy856@mail.sysu.edu.cn
School of Computer Science and Engineering, SYSU, Guangzhou, China
HCP-Lab
I am currently an Associate Professor at the School of Computer Science and Engineering, Sun Yat-sen University (SYSU). I am a core member of the HCP Lab led by Prof. Liang Lin. I obtained my Ph.D. degree from Xidian University in 2019.
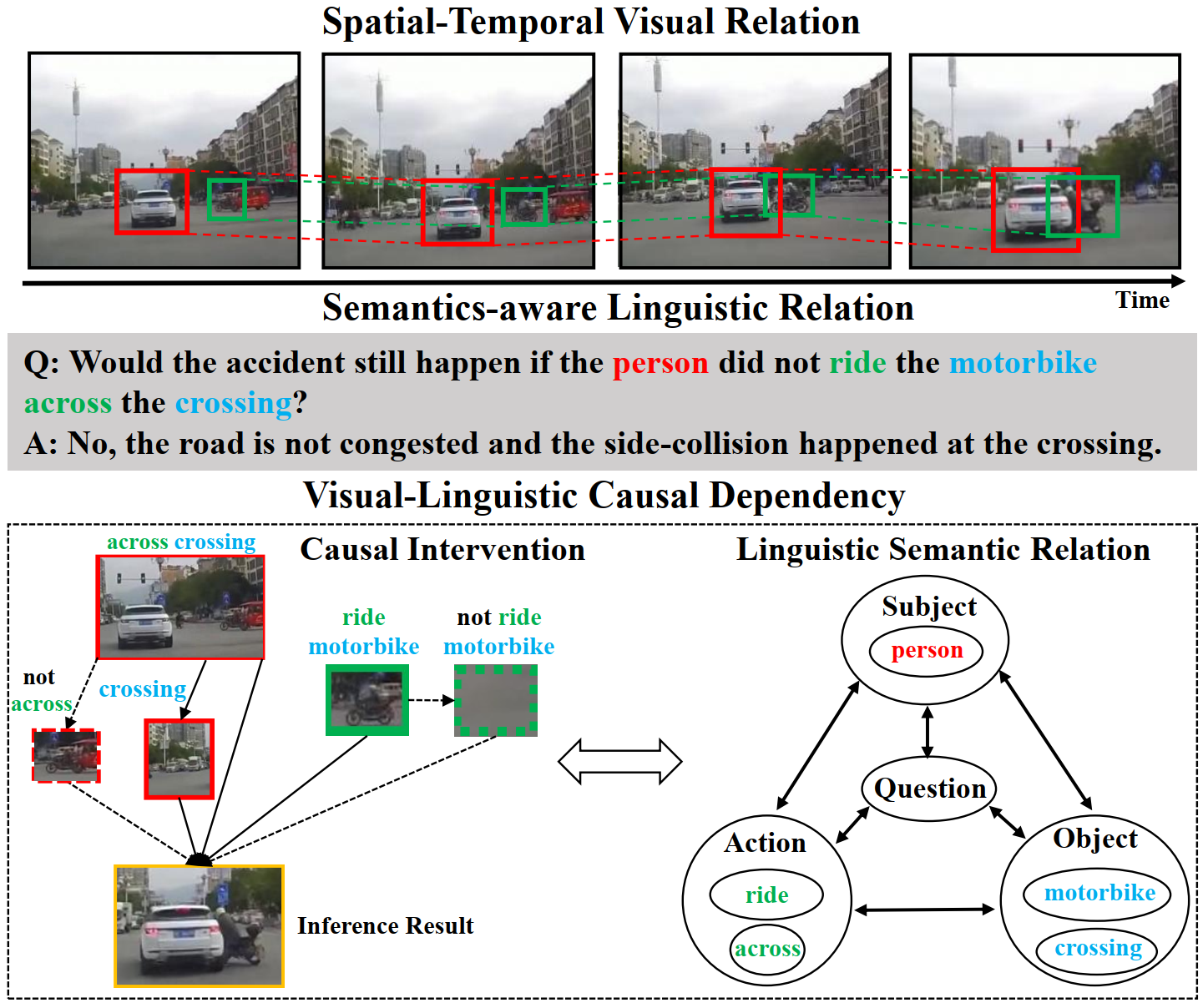
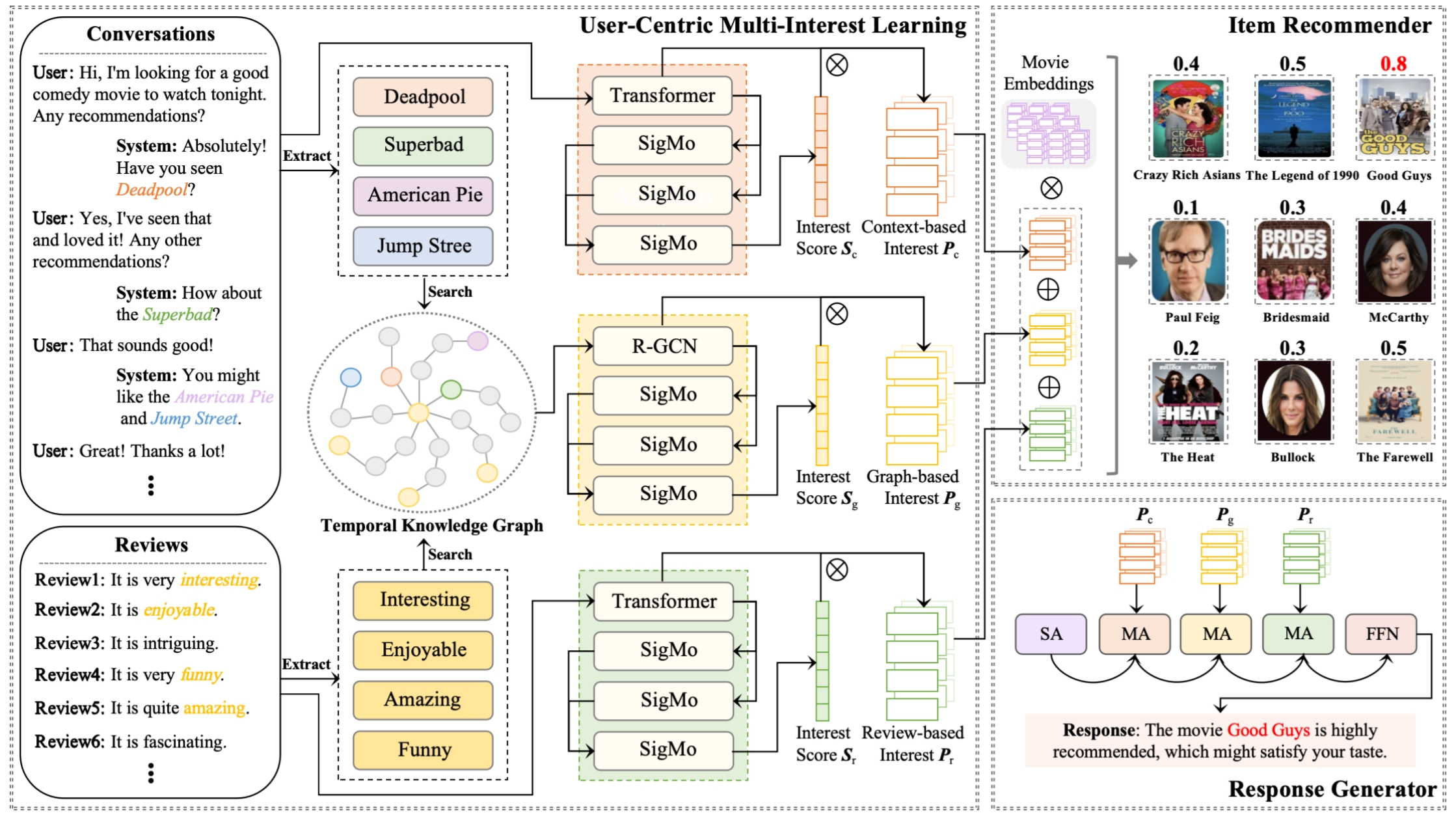
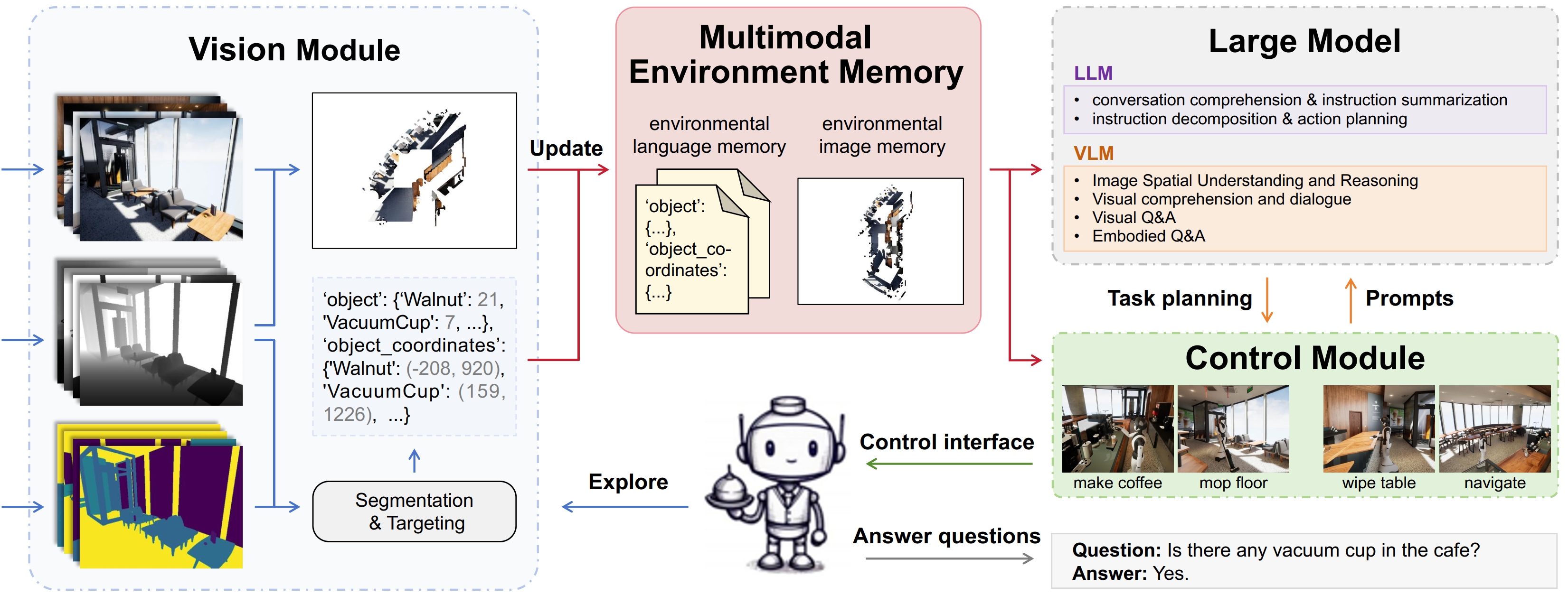
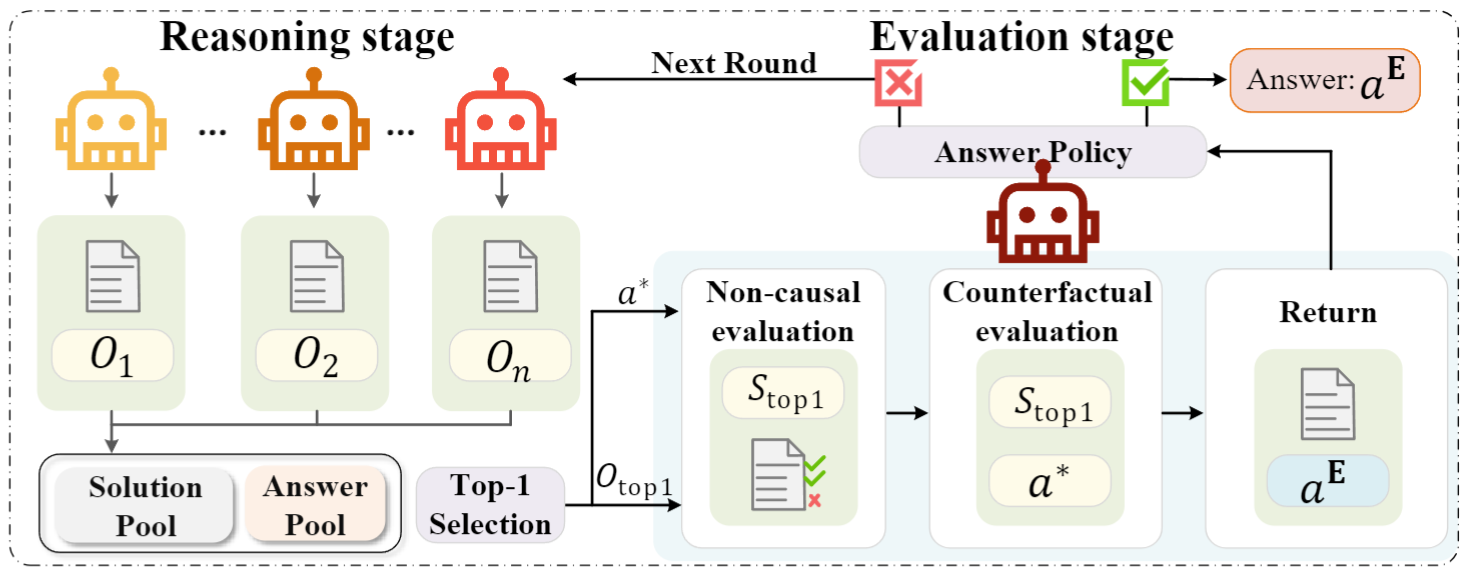
My research primarily focuses on Embodied AI, Multimodal Spatial Perception & Reasoning, and Causal Inference. I have published over 50 papers in top-tier conferences and journals, including TPAMI, TIP, TMECH, TKDE, CVPR, ICCV, and ACM MM. Several of my works have been selected as Oral/Highlight presentations or ESI Highly Cited Papers. I also authored the book "Multimodal Large Models: The New Paradigm of Artificial General Intelligence". 中文主页
Recruiting
Our team has sufficient computing resources and robotic hardware. I am looking for self-motivated Ph.D. students, Master students, and Research Interns who are interested in Embodied AI and Multimodal Reasoning. Please email me your CV if interested.
Research Interests
Selected Awards
- Outstanding Teaching Achievement of Guangdong Province (2nd Prize), 2025
- Excellent Author of PHE (Publishing House of Electronics Industry), 2024
- CCF ChinaSoft 2023 Challenge (3rd Prize)
- 3rd Guangdong Province Young CS Academic Show (1st Prize), 2023
- National Scholarship for PhD Students, 2018