Deep Image-to-Video Adaptation and Fusion Networks for Action Recognition
IEEE Transactions on Image Processing 2020
 orcid.org/0000-0002-9423-9252
orcid.org/0000-0002-9423-9252Homepage: https://yangliu9208.github.io/home/
Abstract
Existing deep learning methods for action recognition in videos require a large number of labeled videos for training, which is labor-intensive and time-consuming. For the same action, the knowledge learned from different media types, e.g., videos and images, may be related and complementary. However, due to the domain shifts and heterogeneous feature representations between videos and images, the performance of classifiers trained on images may be dramatically degraded when directly deployed to videos without effective domain adaptation and feature fusion methods. In this paper, we propose a novel method, named Deep Image-to-Video Adaptation and Fusion Networks (DIVAFN), to enhance action recognition in videos by transferring knowledge from images using video keyframes as a bridge. The DIVAFN is a unified deep learning model, which integrates domain-invariant representations learning and cross-modal feature fusion into a unified optimization framework. Specifically, we design an efficient cross-modal similarities metric to reduce the modality shift among images, keyframes and videos. Then, we adopt an autoencoder architecture, whose hidden layer is constrained to be the semantic representations of the action class names. In this way, when the autoencoder is adopted to project the learned features from different domains to the same space, more compact, informative and discriminative representations can be obtained. Finally, the concatenation of the learned semantic feature representations from these three autoencoders are used to train the classifier for action recognition in videos. Comprehensive experiments on four real-world datasets show that our method outperforms some state-of-the-art domain adaptation and action recognition methods.
Model
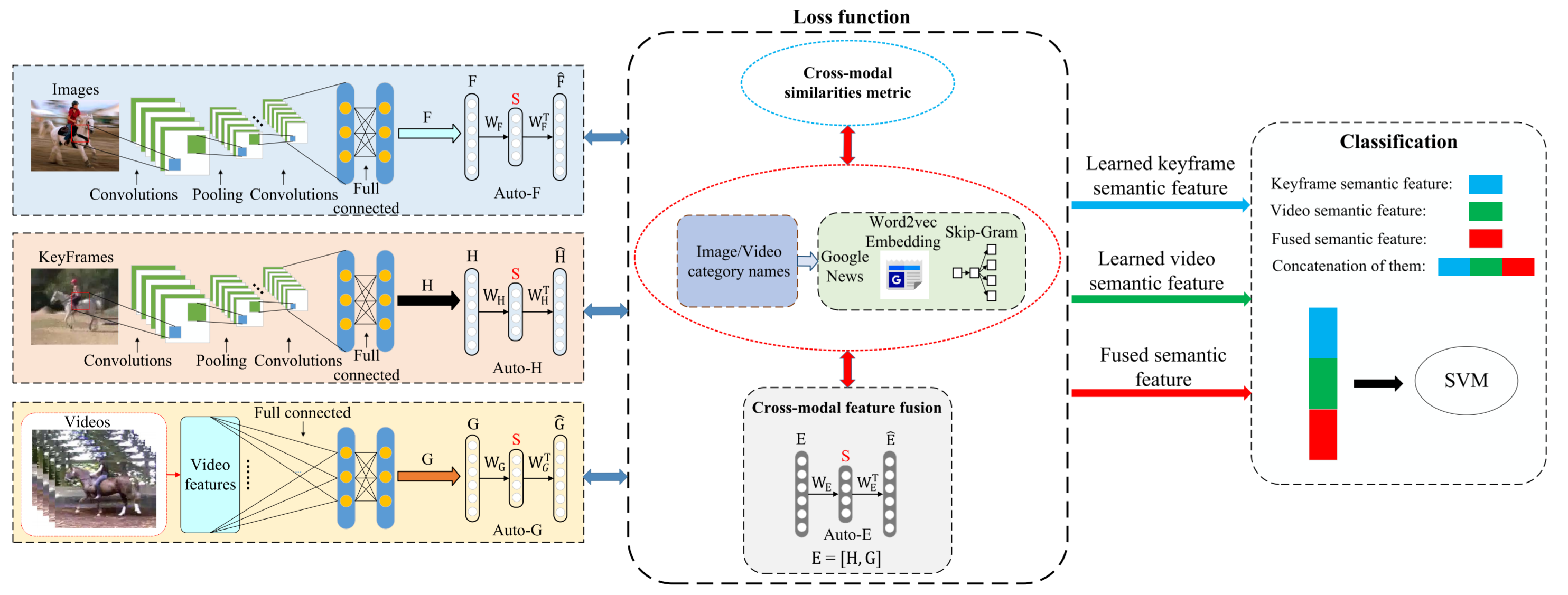
Figure 1: Framework of our proposed DIVAFN.
Network architecture

Figure 2: Configuration of the deep neural network for image modality. “f” denotes the number of convolutional filters and their receptive field size, “st” denotes the convolutional stride, “pad” denotes the number of pixels to add to each size of the input, “LRN” denotes whether Local Response Normalization (LRN) is applied or not, and “pool” denotes the downsampling factor.
Figure 3: Configuration of the deep neural network for keyframe modality.

Figure 4: Configuration of the deep neural network for video modality
Environment
DIVAFN: MatlabR2016b, Matconvnet-1.0-beta25, Windows10
C3D feature extraction: Caffe, Ubuntu16.04 LTS
Word2Vec vectors extraction: python, Ubuntu16.04 LTS
Prerequisite
Install Matconvnet, vlfeat and LibSVM.
Datasets

Stanford40->UCF101 dataset can be downloaded here. Stanford40
ASD->UCF101 dataset can be downloaded here. ASD
EAD->HMDB51 dataset can be downloaded here. EAD, HMDB51
BU101->UCF101 dataset can be downloaded here. BU101, UCF101
Usage
The codes can be downloaded in BaiduCloud or GoogleCloud.
-
Extract keyframes for each video dataset. Codes can be downloaded BaiduCloud(Extraction code: l22w) or GoogleCloud.
-
Extract C3D or IDT+LLC encoding BaiduCloud(Extraction code: mylt) or GoogleCloud features for videos.
-
If you have extracted the C3D features, then you need to transform the C3D binaries into MAT format. Codes can be downloaded BaiduCloud(Extraction code: zon1) or GoogleCloud.
-
Extract the semantic representations (word2vec or attribute) for action class names for each video dataset. Codes can be downloaded BaiduCloud(Extraction code: wdwa) or GoogleCloud.
Run “UCF101_word2vec.py” to caculate the word2vec vectors for UCF101 dataset.
Run “HMDB51_word2vec.py” to caculate word2vec vectors for HMDB51 dataset.
Then run “TXT_to_Mat.m” to compress the vectors from TXT format to MAT format. -
Execute DIVAFN algorithm. Codes can be downloaded BaiduCloud(Extraction code: 7263) or GoogleCloud.
(1) Preprocess. Run “Data_preprocess_Stanford40_UCF101.m”, “Data_preprocess_ASD_UCF101.m”, “Data_preprocess_EAD_HMDB51.m” and “Data_preprocess_BU101_UCF101.m” to obtain a MAT file which contains images, keyframes, video features, semantic vectors, train_test_split information and action class labels for each image-video task.
(2) DIVAFN. Run “main_DIVAFN_Stanford40_UCF101.m”, “main_DIVAFN_ASD_UCF101.m”, “main_DIVAFN_EAD_HMDB51.m”, “main_DIVAFN_BU101_UCF101.m” to excute the DIVAFN algorithm for each image-video task.
(3) Classification. Run “Classify_train_SAECombinedHashCodes_Stanford40_UCF101.m” to classify the actions in video datasets. Other tasks is executed in the similar way.
If you use the codes or find the work helpful, please kindly consider to cite our paper by:
@article{liu2019deep,
title={Deep image-to-video adaptation and fusion networks for action recognition},
author={Liu, Yang and Lu, Zhaoyang and Li, Jing and Yang, Tao and Yao, Chao},
journal={IEEE Transactions on Image Processing},
volume={29},
pages={3168--3182},
year={2019},
publisher={IEEE}
}
If you have any question about this code, feel free to reach me(liuy856@mail.sysu.edu.cn)
