Semantics-aware Adaptive Knowledge Distillation Networks for Sensor-to-Vision Action Recognition
IEEE Transactions on Image Processing 2021
 orcid.org/0000-0002-9423-9252
orcid.org/0000-0002-9423-9252Homepage: https://yangliu9208.github.io/home/
Abstract
Existing vision-based action recognition is susceptible to occlusion and appearance variations, while wearable sensors can alleviate these challenges by capturing human motion with one-dimensional time-series signals (e.g. acceleration, gyroscope and orientation). For the same action, the knowledge learned from vision sensors (videos or images) and wearable sensors, may be related and complementary. However, there exists significantly large modality difference between action data captured by wearable-sensor and vision-sensor in data dimension, data distribution and inherent information content. In this paper, we propose a novel framework, named Semantics-aware Adaptive Knowledge Distillation Networks (SAKDN), to enhance action recognition in vision-sensor modality (videos) by adaptively transferring and distilling the knowledge from multiple wearable sensors. The SAKDN uses multiple wearable-sensors as teacher modalities and uses RGB videos as student modality. Specifically, we transform one-dimensional time-series signals of wearable sensors to two-dimensional images by designing a gramian angular field based virtual image generation model. Then, we build a novel Similarity-Preserving Adaptive Multimodal Fusion Module (SPAMFM) to adaptively fuse intermediate representation knowledge from different teacher networks. To fully exploit and transfer the knowledge of multiple well-trained teacher networks to the student network, we propose a novel Graph-guided Semantically Discriminative Mapping (GSDM) loss, which utilizes graph-guided ablation analysis to produce a good visual explanation highlighting the important regions across modalities and concurrently preserving the interrelations of original data. Experimental results on Berkeley-MHAD, UTDMHAD and MMAct datasets well demonstrate the effectiveness of our proposed SAKDN for adaptive knowledge transfer from wearable-sensors modalities to vision-sensors modalities.
Model
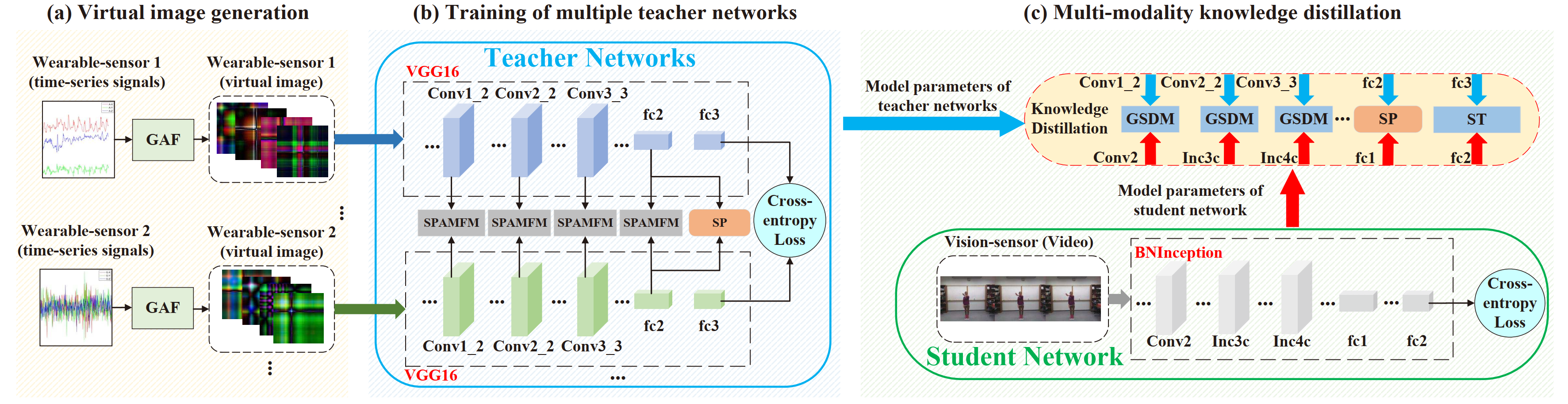 Figure 1: Framework of our proposed SAKDN.
Figure 1: Framework of our proposed SAKDN.
Datasets
Since the link of Berkeley-MHAD cannot be accessed, we give the baiduyun download links, please download the following three files:
GAF Data
The extracted GAF images for three datasets can be downloaded:
UTD-MHAD
Berkeley-MHAD
MMAct
Glove Extraction
Please run Glove.py using the glove.840B.300d.txt.
Codes
The code is available now!
For example, in the UTD dataset:
Step1: Extract the GAF images using matlab codes.
Step2: Run 1_UTD_SemanticFusion.py to train the teacher model.
Step3: Run 2_run_UTD_All_SemanticAblationFusion_distill.py to conduct knowledge distillation.
@article{liu2021semantics,
author={Liu, Yang and Wang, Keze and Li, Guanbin and Lin, Liang},
journal={IEEE Transactions on Image Processing},
title={Semantics-Aware Adaptive Knowledge Distillation for Sensor-to-Vision Action Recognition},
year={2021},
volume={30},
number={},
pages={5573-5588},
doi={10.1109/TIP.2021.3086590}
}
If you have any question about this code, feel free to reach me (liuy856@mail.sysu.edu.cn)
